Яндекс выложил в опенсорс один из крупнейших в мире датасетов для развития рекомендательных систем

Яндекс выложил в открытый доступ один из крупнейших в мире датасетов для развития рекомендательных систем – Yambda (YAndex Music Billion-interactions DAtaset). С помощью Yambda ученые, исследователи и вузы со всего мира смогут тестировать и улучшать рекомендательные алгоритмы.
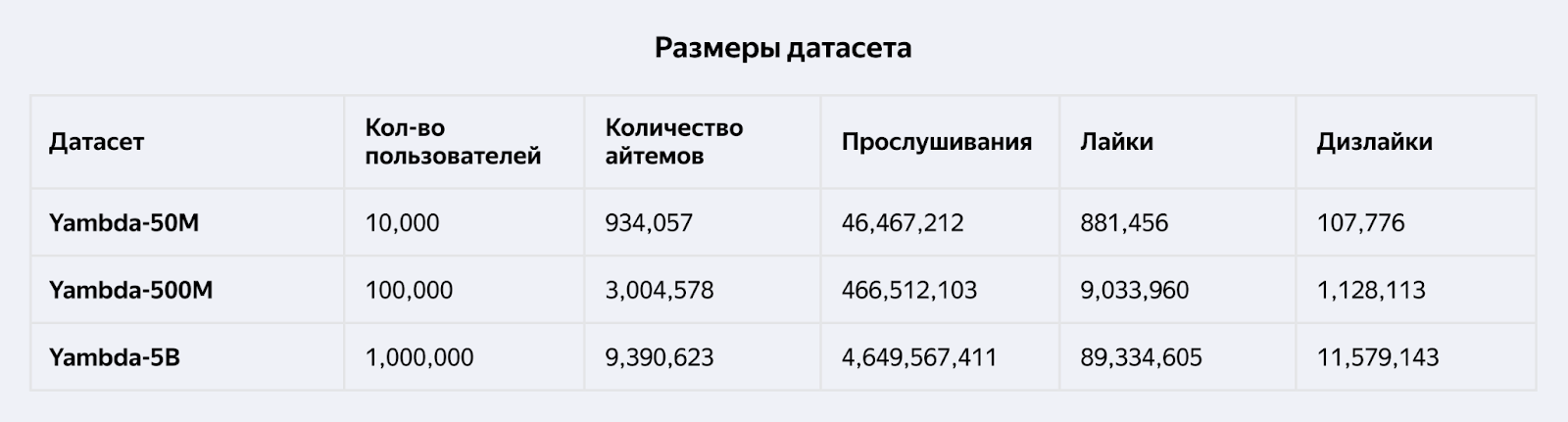
Датасет в трех вариантах: с полной версией данных и с уменьшенными. Разработчики могут выбрать тот вариант, который соответствует их задаче и подходит под вычислительные ресурсы.
Александр Плошкин, руководитель направления по развитию качества персонализации в Яндексе:
Рекомендательные алгоритмы помогают людям находить нужные товары, фильмы, музыку и многое другое – именно они лежат в основе сервисов от интернет-магазинов до онлайн-кинотеатров. Развитие этих алгоритмов напрямую зависит от научных исследований, для которых нужны качественные и объемные датасеты. При этом опенсорс-датасеты чаще всего невелики по размеру или уже устарели, так как коммерческие компании, которые накапливают терабайты данных, редко их публикуют. Это создает разрыв между академическими исследованиями и потребностями бизнеса.
Публикация больших открытых датасетов наподобие Yambda помогает решить эту проблему.
Yambda создан на основе обезличенных данных Яндекс Музыки, но подходит для оценки качества любых рекомендательных систем, так как в их основе лежат общие алгоритмы.
Данные датасета доступны на HuggingFace, код для оценки замеров – на GitHub.
Напомним, ранее Яндекс обновил опенсорс-фреймворк DivKit: верстка мобильных интерфейсов стала проще.


