Это есть только в MySQL

И MariaDB!
Как можно в команде SELECT при генерации данных в столбцы использовать значения других столбцов, не используя запросы из запросов и CTE.
Значения в некоторые столбцы могут формироваться сложным расчётами или подзапросами. Теперь представь, что при определённом получаемом значении в одном из таких столбцов, значение в соседнем столбце нужно формировать по-другому, или даже своим подзапросом на основании полученного значения в предыдущем столбце. Как реализовать подобное, не прибегая к запросу из получаемой таблицы данных и не используя CTE?
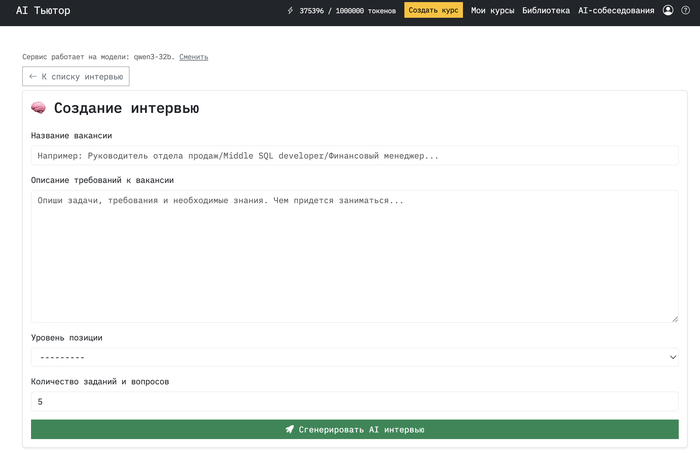
В СУБД MySql и MariaDB есть пользовательские переменные (те, что с собачкой @), которые можно использовать прямо пока выводятся данные командой SELECT, строчка за строчкой. Посмотри (в примере ниже переменная @id_table):
В ПРЕДПОСЛЕДНИЙ(!) столбец формируется значение идентификатора некоторого столика ресторана.
В ПОСЛЕДНИЙ(!) столбец рассчитывается количество свободных мест того столика ресторана, идентификатор которого выведен в предыдущем столбце. В пользовательскую переменную @id_table будет положено некоторое значение, оно же и будет выведено в качестве данных этого столбца. В следующий столбец подзапрос получит данные, опираясь на значение этой переменной. Главное, чтобы эти столбцы формировать в указанном порядке. Сначала столбец, в результате расчёта которого получим значение в переменную, а затем столбец, который будет использовать значение этой переменной. Удобно и легко, да? И эта возможность — лишь верхушка айсберга возможностей использования пользовательских переменных!
В примере выше для каждой строки такой расчёт выводит данные независимо от предыдущей строки, так как в каждой новой строке переменная @id_table получает новое значение и по-новой выполняется подзапрос на основании её значения.
Ещё про пользовательские переменные я писал здесь.
Больше полезного и интересного материала про SQL и базы данных в Телеграм-канале Пишем на SQL.
Буду рад лайку, если понравилась статья!